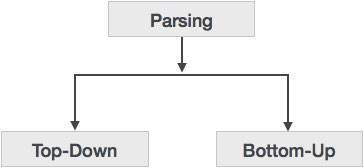
Syntax analyzers follow production rules defined by means of context-free grammar. The way the production rules are implemented (derivation) divides parsing into two types : top-down parsing and bottom-up parsing.
Top-down Parsing
When the parser starts constructing the parse tree from the start symbol and then tries to transform the start symbol to the input, it is called top-down parsing.
- Recursive descent parsing : It is a common form of top-down parsing. It is called recursive as it uses recursive procedures to process the input. Recursive descent parsing suffers from backtracking.
- Backtracking : It means, if one derivation of a production fails, the syntax analyzer restarts the process using different rules of same production. This technique may process the input string more than once to determine the right production.
Bottom-up Parsing
As the name suggests, bottom-up parsing starts with the input symbols and tries to construct the parse tree up to the start symbol.
Example:
Input string : a + b * c
Production rules:
S → E
E → E + T
E → E * T
E → T
T → id
Let us start bottom-up parsing
a + b * c
Read the input and check if any production matches with the input:
a + b * c
T + b * c
E + b * c
E + T * c
E * c
E * T
E
S
Backtracking
One solution to parsing would be to implement backtracking. Based on the information
the parser currently has about the input, a decision is made to go with one particular
production. If this choice leads to a dead end, the parser would have to backtrack to that
decision point, moving backwards through the input, and start again making a different
choice and so on until it either found the production that was the appropriate one or ran
out of choices. For example, consider this simple grammar:
S –> bab | bA
A –> d | cA
Let’s follow parsing the input bcd. In the trace below, the column on the left will be the
expansion thus far, the middle is the remaining input, and the right is the action
attempted at each step:
S bcd Try S –> bab
bab bcd match b
ab cd dead-end, backtrack
S bcd Try S –> bA
bA bcd match b
A cd Try A –> d
d cd dead-end, backtrack
A cd Try A –> cA
cA cd match c
A d Try A –> d
d d match d
Success!
As you can see, each time we hit a dead-end, we backup to the last decision point,
unmake that decision and try another alternative. If all alternatives have been
exhausted, we back up to the preceding decision point and so on. This continues until
we either find a working parse or have exhaustively tried all combinations without
success.
A number of authors have described backtracking parsers; the appeal is that they can be
used for a variety of grammars without requiring them to fit any specific form. For a
small grammar such as above, a backtracking approach may be tractable, but most
programming language grammars have dozens of nonterminals each with several
3
options and the resulting combinatorial explosion makes a this approach very slow and
impractical. We will instead look at ways to parse via efficient methods that have
restrictions about the form of the grammar, but usually those requirements are not so
onerous that we cannot rearrange a programming language grammar to meet them.
Source code (top down parser with backtracking) implementation in C
For a given Grammer as example:S -> cAdA -> ab|a#include<stdio.h>#include<string.h>void check(void);void set_value_backtracking(void);void get_value_backtracking(void);void display_output_string(void);int iptr=0,optr=0,current_optr=0;char output_string[20],current_output_string[20],input_string[20],temp_string[20];int main(){printf("\nEnter the string to check: ");scanf("%s",input_string);check();return 0;}void check(void){//Rule 1, S->cAd//Rule 2, A->ab|aint flag=1,rule2_index=1;strcpy(output_string,"S");printf("\nThe output string in different stages are:\n");while(iptr<=strlen(input_string)){if(strcmp(output_string,temp_string)!=0){display_output_string();}if((iptr!=strlen(input_string)) || (optr!=strlen(output_string))){if(input_string[iptr]==output_string[optr]){iptr=iptr+1;optr=optr+1;}else{if(output_string[optr]=='S'){memset(output_string,0,strlen(output_string));strcpy(output_string,"cAd");}else if(output_string[optr]=='A'){set_value_backtracking();if(rule2_index==1){memset(output_string,0,strlen(output_string));strcpy(output_string,"cabd");}else{memset(output_string,0,strlen(output_string));strcpy(output_string,"cad");}}else if(output_string[optr]=='b' && input_string[iptr]=='d'){rule2_index=2;get_value_backtracking();iptr=iptr-1;}else{printf("\nThe given string, '%s' is invalid.\n\n",input_string);break;}}}else{printf("\nThe given string, '%s' is valid.\n\n",input_string);break;}}}void set_value_backtracking(void){ //setting values for backtrackingcurrent_optr=optr;strcpy(current_output_string,output_string);return;}void get_value_backtracking(void){ //backtracking and obtaining previous valuesoptr=current_optr;memset(output_string,0,strlen(output_string));strcpy(output_string,current_output_string);return;}void display_output_string(void){printf("%s\n",output_string);memset(temp_string,0,strlen(temp_string));strcpy(temp_string,output_string);return;}
Recursive Descent
The first technique for implementing a predictive parser is called recursive-descent. A recursive-descent parser consists of several small functions, one for each nonterminal in the grammar. As we parse a sentence, we call the functions that correspond to the left side nonterminal of the productions we are applying. If these productions are recursive, we end up calling the functions recursively. Let’s start by examining some productions from a grammar for a simple Pascal-like programming language. In this programming language, all functions are preceded by the reserved word FUNC: program –> function_list function_list –> function_list function | function function –> FUNC identifier ( parameter_list ) statements What might the C function that is responsible for parsing a function definition look like? It expects to first find the token FUNC, then it expects an identifier (the name of the function), followed by an opening parenthesis, and so on. As it pulls each token from the parser, it must ensure that it matches the expected, and if not, will halt with an error. For each nonterminal, this function calls the associated function to handle its part of the parsing. Check this out: 4 void ParseFunction() { if (lookahead != T_FUNC) { // anything not FUNC here is wrong printf("syntax error \n"); exit(0); } else lookahead = yylex(); // global 'lookahead' holds next token ParseIdentifier(); if (lookahead != T_LPAREN) { printf("syntax error \n"); exit(0); } else lookahead = yylex(); ParseParameterList(); if (lookahead!= T_RPAREN) { printf("syntax error \n"); exit(0); } else lookahead = yylex(); ParseStatements(); } To make things a little cleaner, let’s introduce a utility function that can be used to verify that the next token is what is expected and will error and exit otherwise. We will need this again and again in writing the parsing routines. void MatchToken(int expected) { if (lookahead != expected) { printf("syntax error, expected %d, got %d\n", expected,lookahead); exit(0); } else // if match, consume token and move on lookahead = yylex(); } Now we can tidy up the ParseFunction routine and make it clearer what it does: void ParseFunction() { MatchToken(T_FUNC); ParseIdentifier(); MatchToken(T_LPAREN); ParseParameterList(); MatchToken(T_RPAREN); ParseStatements(); } 5 The following diagram illustrates how the parse tree is built: Here is the production for an if-statement in this language: if_statement –> IF expression THEN statement ENDIF | IF expression THEN statement ELSE statement ENDIF To prepare this grammar for recursive-descent, we must left-factor to share the common parts: if_statement –> IF expression THEN statement close_if close_if –> ENDIF | ELSE statement ENDIF Now, let’s look at the recursive-descent functions to parse an if statement: void ParseIfStatement() { MatchToken(T_IF); ParseExpression(); MatchToken(T_THEN); ParseStatement(); ParseCloseIf(); } void ParseCloseIf() { if (lookahead == T_ENDIF) // if we immediately find ENDIF lookahead = yylex(); // predict close_if -> ENDIF else { MatchToken(T_ELSE); // otherwise we look for ELSE ParseStatement(); // predict close_if -> ELSE stmt ENDIF MatchToken(T_ENDIF); } } When parsing the closing portion of the if, we have to decide which of the two righthand side options to expand. In this case, it isn’t too difficult. We try to match the first token again ENDIF and on non-match, we try to match the ELSE clause and if that doesn’t match, it will report an error. function_list function FUNC parameter_list this part of the tree is parsed by the call to this part is parsed by the call to this part is parsed by the call to statements identifier program 6 Navigating through two choices seemed simple enough, however, what happens where we have many alternatives on the right side? statement –> assg_statement | return_statement | print_statement | null_statement | if_statement | while_statement | block_of_statements When implementing the ParseStatement function, how are we going to be able to determine which of the seven options to match for any given input? Remember, we are trying to do this without backtracking, and just one token of lookahead, so we have to be able to make immediate decision with minimal information— this can be a challenge! To understand how to recognize and solve problem, we need a definition: The first set of a sequence of symbols u, written as First(u) is the set of terminals which start the sequences of symbols derivable from u. A bit more formally, consider all strings derivable from u. If u =>* v, where v begins with some terminal, that terminal is in First(u). If u =>* ε, then ε is in First(u). Informally, the first set of a sequence is a list of all the possible terminals that could start a string derived from that sequence. We will work an example of calculating the first sets a bit later. For now, just keep in mind the intuitive meaning. Finding our lookahead token in one of the first sets of the possible expansions tells us that is the path to follow. Given a production with a number of alternatives: A –> u1 | u2 | ..., we can write a recursive-descent routine only if all the sets First(ui ) are disjoint. The general form of such a routine would be: void ParseA() { // case below not quite legal C, need to list symbols individually switch (lookahead) { case First(u1): // predict production A -> u1 /* code to recognize u1 */ return; case First(u2): // predict production A -> u2 /* code to recognize u2 */ return; .... default: printf("syntax error \n"); exit(0); } } If the first sets of the various productions for a nonterminal are not disjoint, a predictive parser doesn't know which choice to make. We would either need to re-write the grammar or use a different parsing technique for this nonterminal. For programming languages, it is usually possible to re-structure the productions or embed certain rules 7 into the parser to resolve conflicts, but this constraint is one of the weaknesses of the topdown non-backtracking approach. It is a bit trickier if the nonterminal we are trying to recognize is nullable. A nonterminal A is nullable if there is a derivation of A that results in ε (i.e., that nonterminal would completely disappear in the parse string) i.e., ε ∈ First(A). In this case A could be replaced by nothing and the next token would be the first token of the symbol following A in the sentence being parsed. Thus if A is nullable, our predictive parser also needs to consider the possibility that the path to choose is the one corresponding to A =>* ε. To deal with this we define the following: The follow set of a nonterminal A is the set of terminal symbols that can appear immediately to the right of A in a valid sentence. A bit more formally, for every valid sentence S =>* uAv, where v begins with some terminal, and that terminal is in Follow(A). Informally, you can think about the follow set like this: A can appear in various places within a valid sentence. The follow set describes what terminals could have followed the sentential form that was expanded from A. We will detail how to calculate the follow set a bit later. For now, realize follow sets are useful because they define the right context consistent with a given nonterminal and provide the lookahead that might signal a nullable nonterminal should be expanded to ε. With these two definitions, we can now generalize how to handle A –> u1 | u2 | ..., in a recursive-descent parser. In all situations, we need a case to handle each member in First(ui ). In addition if there is a derivation from any ui that could yield ε (i.e. if it is nullable) then we also need to handle the members in Follow(A). void ParseA() { switch (lookahead) { case First(u1): /* code to recognize u1 */ return; case First(u2): /* code to recognize u2 */ return; ... case Follow(A): // predict production A->epsilon if A is nullable /* usually do nothing here */ default: printf("syntax error \n"); exit(0); } } 8 What about left-recursive productions? Now we see why these are such a problem in a predictive parser. Consider this left-recursive production that matches a list of one or more functions. function_list –> function_list function | function function –> FUNC identifier ( parameter_list ) statement void ParseFunctionList() { ParseFunctionList(); ParseFunction(); } Such a production will send a recursive-descent parser into an infinite loop! We need to remove the left-recursion in order to be able to write the parsing function for a function_list. function_list –> function_list function | function becomes function_list –> function function_list | function then we must left-factor the common parts function_list –> function more_functions more_functions –> function more_functions | ε And now the parsing function looks like this: void ParseFunctionList() { ParseFunction(); ParseMoreFunctions(); // may be empty (i.e. expand to epsilon) } Computing first and follow These are the algorithms used to compute the first and follow sets: Calculating first sets. To calculate First(u) where u has the form X1X2...Xn, do the following: a) If X1 is a terminal, add X1 to First(u) and you're finished. b) Else X1 is a nonterminal, so add First(X1) - ε to First(u). a. If X1 is a nullable nonterminal, i.e., X1 =>* ε, add First(X2) - ε to First(u). Furthermore, if X2 can also go to ε, then add First(X3) - ε and so on, through all Xn until the first non-nullable symbol is encountered. b. If X1X2...Xn =>* ε, add ε to the first set. 9 Calculating follow sets. For each nonterminal in the grammar, do the following: 1. Place EOF in Follow(S) where S is the start symbol and EOF is the input's right endmarker. The endmarker might be end of file, newline, or a special symbol, whatever is the expected end of input indication for this grammar. We will typically use $ as the endmarker. 2. For every production A –> uBv where u and v are any string of grammar symbols and B is a nonterminal, everything in First(v) except ε is placed in Follow(B). 3. For every production A –> uB, or a production A –> uBv where First(v) contains ε (i.e. v is nullable), then everything in Follow(A) is added to Follow(B). Here is a complete example of first and follow set computation, starting with this grammar: S –> AB A –> Ca | ε B –> BaAC | c C –> b | ε Notice we have a left-recursive production that must be fixed if we are to use LL(1) parsing: B –> BaAC | c becomes B –> cB' B' –> aACB' | ε The new grammar is: S –> AB A –> Ca | ε B –> cB' B' –> aACB' | ε C –> b | ε It helps to first compute the nullable set (i.e., those nonterminals X that X =>* ε), since you need to refer to the nullable status of various nonterminals when computing the first and follow sets: Nullable(G) = {A B' C} The first sets for each nonterminal are: First(C) = {b ε} First(B') = {a ε} First(B) = {c} First(A) = {b a ε} Start with First(C) - ε, add a (since C is nullable) and ε (since A itself is nullable) 10 First(S) = {b a c} Start with First(A) - ε, add First(B) (since A is nullable). We don’t add ε (since S itself is not-nullable— A can go away, but B cannot) It is usually convenient to compute the first sets for the nonterminals that appear toward the bottom of the parse tree and work your way upward since the nonterminals toward the top may need to incorporate the first sets of the terminals that appear beneath them in the tree. To compute the follow sets, take each nonterminal and go through all the right-side productions that the nonterminal is in, matching to the steps given earlier: Follow(S) = {$} S doesn’t appear in the right hand side of any productions. We put $ in the follow set because S is the start symbol. Follow(B) = {$} B appears on the right hand side of the S –> AB production. Its follow set is the same as S. Follow(B') = {$} B' appears on the right hand side of two productions. The B' –> aACB' production tells us its follow set includes the follow set of B', which is tautological. From B –> cB', we learn its follow set is the same as B. Follow(C) = {a $} C appears in the right hand side of two productions. The production A –> Ca tells us a is in the follow set. From B' –> aACB' , we add the First(B') which is just a again. Because B' is nullable, we must also add Follow(B') which is $. Follow(A) = {c b a $} A appears in the right hand side of two productions. From S –> AB we add First(B) which is just c. B is not nullable. From B' –> aACB' , we add First(C) which is b. Since C is nullable, so we also include First(B') which is a. B' is also nullable, so we include Follow(B') which adds $. It can be convenient to compute the follows sets for the nonterminals that appear toward the top of the parse tree and work your way down, but sometimes you have to circle around computing the follow sets of other nonterminals in order to complete the one you’re on. The calculation of the first and follow sets follow mechanical algorithms, but it is very easy to get tripped up in the details and make mistakes even when you know the rules. Be careful!Implementation of recursive decent parser in C (source code)
typedef enum {ident, number, lparen, rparen, times, slash, plus, minus, eql, neq, lss, leq, gtr, geq, callsym, beginsym, semicolon, endsym, ifsym, whilesym, becomes, thensym, dosym, constsym, comma, varsym, procsym, period, oddsym} Symbol; Symbol sym; void nextsym(void); void error(const char msg[]); int accept(Symbol s) { if (sym == s) { nextsym(); return 1; } return 0; } int expect(Symbol s) { if (accept(s)) return 1; error("expect: unexpected symbol"); return 0; } void factor(void) { if (accept(ident)) { ; } else if (accept(number)) { ; } else if (accept(lparen)) { expression(); expect(rparen); } else { error("factor: syntax error"); nextsym(); } } void term(void) { factor(); while (sym == times || sym == slash) { nextsym(); factor(); } } void expression(void) { if (sym == plus || sym == minus) nextsym(); term(); while (sym == plus || sym == minus) { nextsym(); term(); } } void condition(void) { if (accept(oddsym)) { expression(); } else { expression(); if (sym == eql || sym == neq || sym == lss || sym == leq || sym == gtr || sym == geq) { nextsym(); expression(); } else { error("condition: invalid operator"); nextsym(); } } } void statement(void) { if (accept(ident)) { expect(becomes); expression(); } else if (accept(callsym)) { expect(ident); } else if (accept(beginsym)) { do { statement(); } while (accept(semicolon)); expect(endsym); } else if (accept(ifsym)) { condition(); expect(thensym); statement(); } else if (accept(whilesym)) { condition(); expect(dosym); statement(); } else { error("statement: syntax error"); nextsym(); } } void block(void) { if (accept(constsym)) { do { expect(ident); expect(eql); expect(number); } while (accept(comma)); expect(semicolon); } if (accept(varsym)) { do { expect(ident); } while (accept(comma)); expect(semicolon); } while (accept(procsym)) { expect(ident); expect(semicolon); block(); expect(semicolon); } statement(); } void program(void) { nextsym(); block(); expect(period); }
Thank you for spamming
ReplyDelete